KI kommt nicht allein
21. Oktober 2024
Bislang sind wir in unserer Serie darauf eingegangen, welches grundlegende technische Wissen erforderlich ist, um generative KI sinnvoll einzusetzen und den größten Nutzen daraus zu ziehen. Stattliche sieben Teile gab es schon: im ersten Teil unserer Serie haben wir uns mit den verschiedenen Arten von KI beschäftigt, im zweiten Teil einen näheren Blick auf die generative KI und ihre Besonderheiten geworfen, im dritten Teil die verschiedenen Modelle betrachtet, im vierten Teil erfahren, welche Eigenschaften von Sprachmodellen wir beim Prompten im Hinterkopf haben müssen, im fünften Teil die Prompting-Praxis kennengelernt, im sechsten Teil den Zusammenhang von generativer KI und Daten betrachtet und im siebten Teil einen ersten Blick auf RAG geworfen.
Bevor wir uns weiteren technischen Themen wie dem Training von Sprachmodellen zuwenden, wollen wir einen Blick darauf werfen, welche anderen Hürden zu überwinden sind. Denn die erfolgreiche Einführung von KI hängt nicht nur vom spezifischen KI-Know-how ab.
Digital und datenlastig
Wenn wir von KI-Projekten sprechen, dann sprechen wir implizit auch immer von digitalen und Datenprojekten. Wir haben es also mit drei Ebenen zu tun.
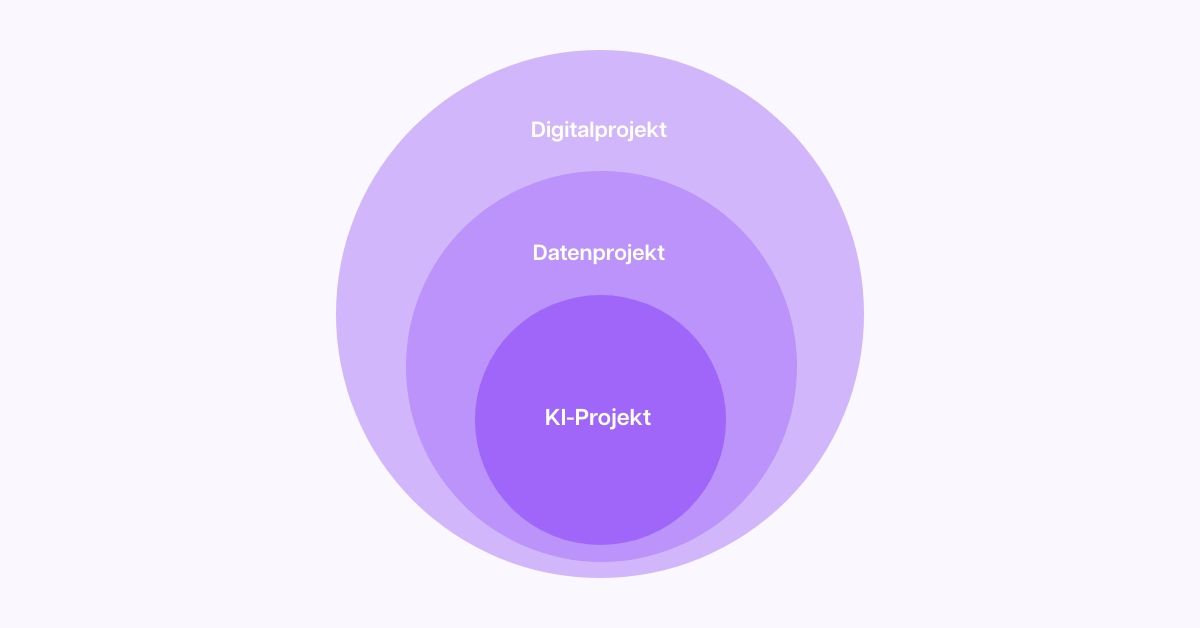
Denn wenn KI beispielsweise dazu genutzt werden soll, internes Unternehmenswissen zugänglich zu machen, dann kann die KI das nicht von allein. Wir werden vielmehr eine Applikation bauen, welche die Unternehmensdaten mit der KI verbindet und der KI sagt, dass sie immer zuerst in die Unternehmensdaten gucken und nach einer Antwort suchen soll, bevor sie auf ihre eigenen Daten zugreift. Und eine solche App ist das Ergebnis eines digitalen Projekts.
Die Daten sind die zweite Ebene. Unternehmensinformationen liegen in verschiedenen Quellen, in unterschiedlichen Formaten und vor allem in einer nicht immer gleichen Qualität vor. Auch die KI folgt dem Prinzip Sh*t in, sh*t out. Wenn Daten widersprüchlich, falsch oder auch nur lückenhaft sind, ist die KI in der Regel nicht intelligent genug, um das zu erkennen und die richtigen Schlüsse daraus zu ziehen. Wir müssen also erst einmal die Daten so aufbereiten, dass die KI damit arbeiten kann, damit wir sinnvolle Ergebnisse erhalten. Das ist das Datenprojekt, das wir stemmen müssen.
Erst jetzt kommt die dritte Ebene, die KI. Bei der Nutzung von generativer KI haben wir gelernt, dass wir es mit einem nicht-deterministischen System zu tun haben. Im Klartext bedeutet das - es gibt Überraschungen. Während wir bei der Ad-hoc-Nutzung mit den unerwarteten Antworten der KI gut umgehen können, indem wir unsere Frage ändern oder einfach nur ein zweites Mal stellen, ist das bei einer KI-Applikation nicht akzeptabel. Denn wenn Mitarbeitende Unternehmensinformationen abfragen, dann erwarten sie, dass diese bei entsprechend gut aufbereiteten Datenquellen korrekt sind. Deshalb sind KI-Projekte noch viel iterativer als digitale und Datenprojekte. Die Schwachstellen werden durch Tests gefunden und immer wieder behoben, bis die Antwortqualität passt.
Es lohnt sich
Es hat sich herumgesprochen, dass der Einsatz von KI enorme Effizienzgewinne bringen kann. Wenn Unternehmenswissen zugänglich gemacht wird, sparen sich Wissensarbeitende bis zu drei Stunden Arbeit am Tag - haben wir im siebten Teil dieser Serie gelernt. Es lohnt sich also. Auch wenn wir in diesem Teil über die Schwierigkeiten gesprochen haben, dann ist das positiv. Denn mit der richtigen Herangehensweise und einem realistischen Erwartungsmanagement gelingen KI-Projekte trotz ihrer Komplexität.
Wie das im Einzelnen geht, werden wir in den nächsten Teilen sehen.