RAG funktioniert, vorausgesetzt die Unternehmensdaten passen
30. September 2024
Nachdem wir uns im ersten Teil unserer Serie mit den verschiedenen Arten von KI beschäftigt, im zweiten Teil einen näheren Blick auf die generative KI und ihre Besonderheiten geworfen, im dritten Teil die verschiedenen Modelle betrachtet, im vierten Teil erfahren haben, welche Eigenschaften von Sprachmodellen wir beim Prompten im Hinterkopf haben müssen, im fünften Teil die Prompting-Praxis kennengelernt haben und im sechsten Teil den Zusammenhang von generativer KI und Daten betrachtet haben, geht es in diesem Teil darum, wie wir mit KI und unternehmensinternen Daten arbeiten können.
Wir haben gesehen, dass Daten beim Einsatz von generativer KI den Unterschied ausmachen. Prompten ist schnell gelernt. Der Ad-hoc-Einsatz von Chatbots ist weit verbreitet und bringt kurz- bis mittelfristig kaum Wettbewerbsvorteile. Doch Unternehmen, die Sprachmodelle mit eigenen Daten verknüpfen, sichern sich einen Mehrwert, den andere nicht einfach kopieren können.
Und nicht nur das: Vielleicht verbringst du täglich viel Zeit mit der Suche nach Informationen. Laut IDC und anderer Marktforschungsunternehmen verbringen Wissensarbeitende bis zu drei Stunden pro Tag mit der Suche nach Informationen. Diese Zeit lässt sich produktiver nutzen, wenn die Unternehmensinformationen so zugänglich sein, dass du
- sie durch eine Frage an einen Chatbot findest
- sicher sein kannst, dass es sich um die aktuelle Fassung der Informationen handelt
- eine Antwort vom Chatbot erhältst, die die Informationen richtig wiedergibt
Wie erreichen wir das?
Start mit einzelnen Dokumenten
Chatbots wie ChatGPT, aber auch unternehmensinterne Chatbots ermöglichen den Upload von Dateien, zum Beispiel von Texten oder Datensätzen. Schon so lässt sich mit internen Informationen ohne zusätzlich Tools arbeiten: wir laden ein oder mehrere Dokumente hoch und befragen sie.
Doch dabei treten oft zwei Probleme auf:
- Die Auswahl der richtigen Dokumente bleibt genauso schwierig wie zuvor, da du sie vornehmen musst.
- Die Antwort des Chatbots ist nicht immer korrekt, es kommt zu Halluzinationen.
GPTs
Für das erste Problem bietet OpenAI eine Lösung: das Anlegen von GPTs und Speichern der korrekten Dokumentversion in diesem GPT. Die Arbeit, die aktuelle Fassung eines Dokuments zu finden, fällt nur einmal an. Danach können sich alle Nutzer*innen sicher sein, dass sie die richtigen Informationen nutzen.
Das zweite Problem der Halluzinationen bleibt jedoch bestehen. Selbst mit guten Prompts treten Fehler auf, die oft über die akzeptable Fehlertoleranz hinausgehen.
Chunking
Liegt die Lösung nicht im Prompten, müssen wir die Bereitstellung von Unternehmensinformationen überdenken. Bei großen Dokumenten und insbesondere bei Präsentationen, PDFs mit unterschiedlichen Inhalten wie Texten, Tabellen und Bildern, sowie bei komplexen Excel-Tabellen wandern Sprachmodelle gerne ins Reich der Fantasie ab.
Um dieses Problem in den Griff zu bekommen, gibt es die Methode des Chunkings. Dateien werden von allem überflüssigen Ballast befreit und in kleinere Teile zerlegt, die dem Sprachmodell dann als eigenständige Dateien zur Verfügung gestellt werden. Inhaltlich sinnvolles Chunking ist eine komplexe Aufgabe und ein gut behütetes Geheimnis von spezialisierten KI-Dienstleistern, die diese Aufgabe übernehmen.
Die Ergebnisse werden mit dem Chunking erheblich zuverlässiger, doch kommt die Methode nicht nur bei großen Datenmengen an ihre Grenzen. Sie ist bei dynamischen Daten nicht praktikabel.
RAG
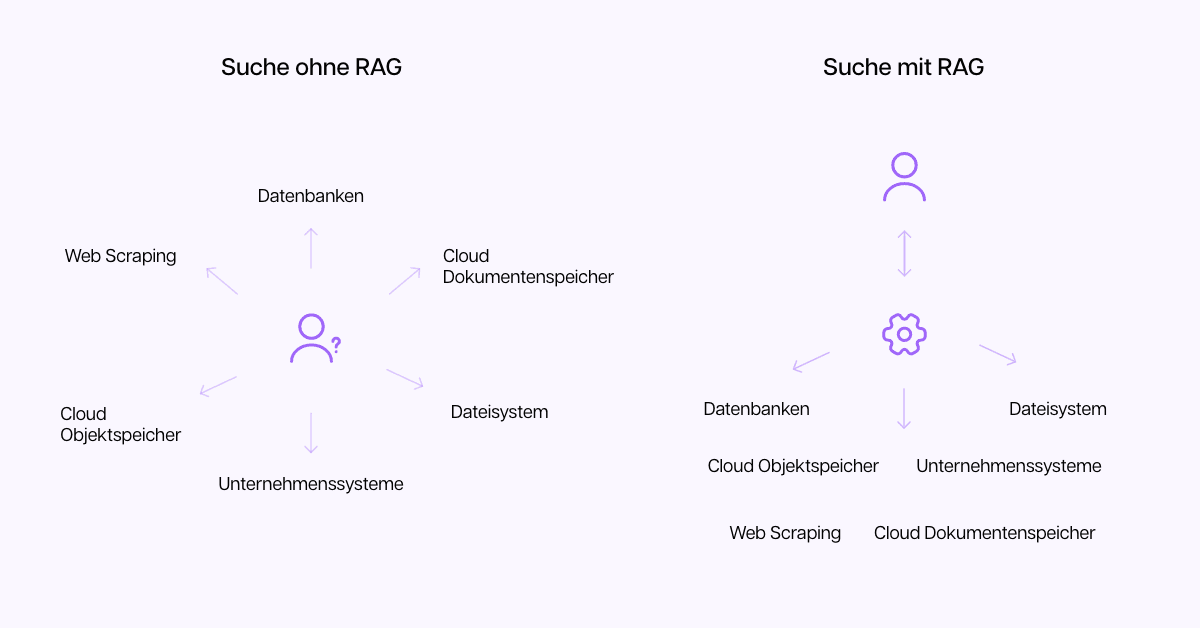
Hier kommt Retrieval Augmented Generation - kurz RAG - ins Spiel. RAG kombiniert unternehmensinterne Daten mit einem Sprachmodell, so dass das Sprachmodell die internen Daten immer bevorzugt. Das Modell sucht immer erst in den unternehmenseigenen Daten nach einer Antwort, bevor es auf allgemeines Wissen zurückgreift. Dadurch erhöht sich die Genauigkeit der Antworten deutlich.
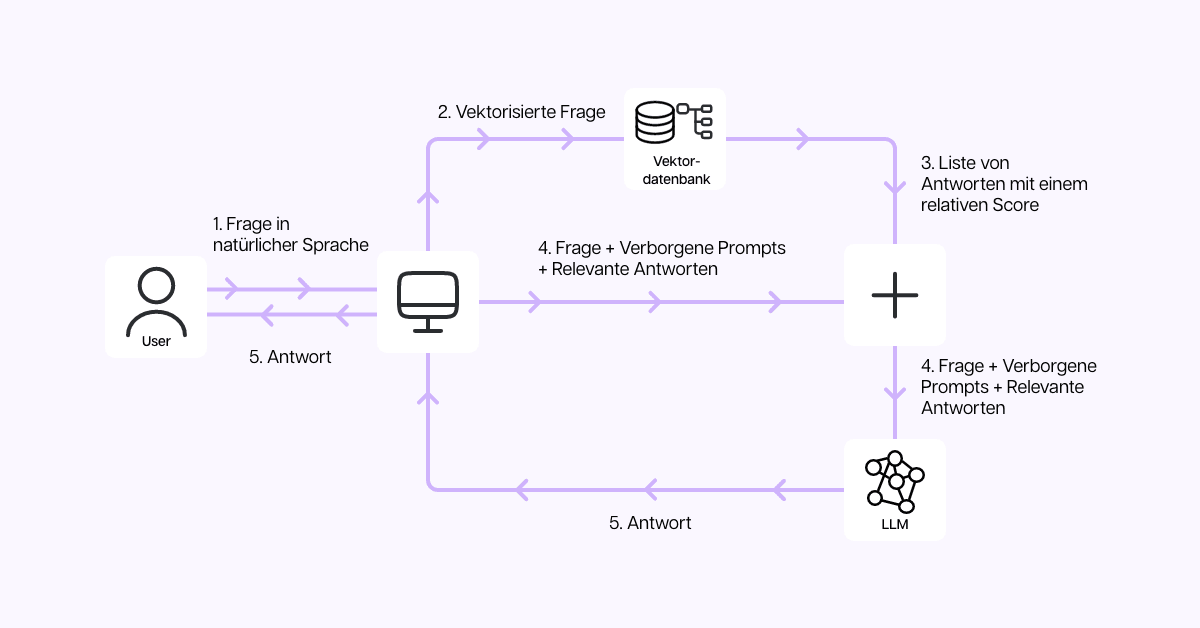
RAG hat sich schnell durchgesetzt, weil es kostengünstiger als Fine-Tuning ist und das Problem der Halluzinationen weitestgehend löst. Zudem sind die Datenquellen klar nachvollziehbar, was Vertrauen schafft.
Ein RAG-Projekt ist der Prototyp eines KI-Projekts. Es kann klein beginnen, etwa mit wenigen Datenquellen, und lässt sich iterativ erweitern. Bereits eine kleine Datenbank kann die Effizienz und Qualität in einer Fachabteilung steigern. Wächst ihr Umfang und die Informationen, die dort abgelegt werden, wachsen auch Qualität und Effizienz.
Doch so schön es klingt, ist die Realität oft nicht. Denn der Erfolg von RAG hängt von der Datenqualität weiteren Faktoren ab, die wir aus digitalen Projekten kennen. Dazu mehr in der nächsten Folge.