RAG works - if company data matches
September 30, 2024
After looking at the different types of AI in the first part of our series, taking a closer look at generative AI and its special features in the second part, looking at the different models in the third part, and finding out which properties of language models we need to consider when prompting in the fourth part, learning about the practice of prompting in the fifth part, and looking ath the connection between generative AI and data in the sixth part, this part is about how we can work with AI and internal company data.
We have seen that data makes all the difference when using generative AI. Prompting is quickly learned. The ad hoc use of chatbots is widespread and provides little competitive advantage in the short to medium term. However, companies that combine speech models with their own data gain an edge that others cannot easily replicate.
What's more, you probably spend a lot of time looking for information every day. According to IDC and other research firms, knowledge workers spend up to three hours a day searching for information. This time can be used more productively if corporate information is accessible in a way that you can
- find it by asking a chatbot a question
- be confident that they have the latest version of the information
- get an answer from the chatbot that accurately reflects the information
How do we achieve this?
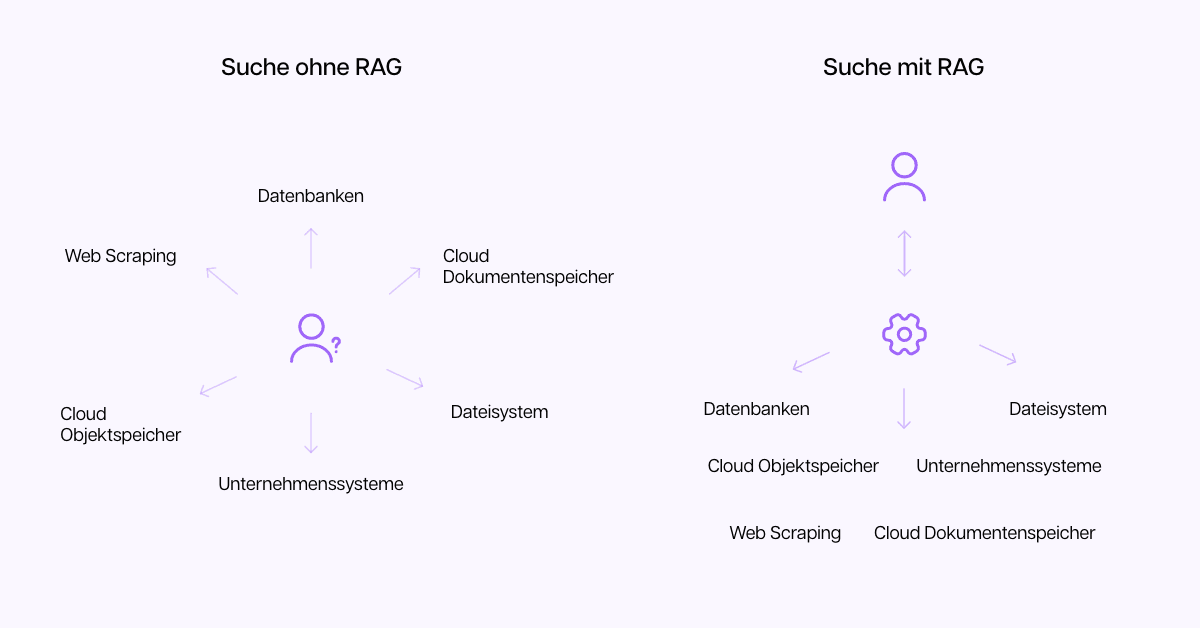
Start with individual documents
Chatbots like ChatGPT, but also internal company chatbots, allow you to upload files, such as text or data sets. This allows us to work with internal information without additional tools: we upload one or more documents and ask them questions.
However, this often leads to two problems:
- Selecting the right documents remains as difficult as before, because you have to do it.
- The chatbot's answer is not always correct, hallucinations occur.
GPTs
OpenAI provides a solution to the first problem: creating GPTs and storing the correct document version in that GPT. The work of finding the current version of a document is required only once. After that, all users can be sure that they are using the correct information.
The second problem, however, remains. Even with good prompts, errors occur that often exceed the acceptable error tolerance.
Chunking
If prompting is not the answer, then we need to rethink how we deliver corporate information. For large documents, especially presentations, PDFs with mixed content such as text, tables, and images, and complex Excel spreadsheets, language models tend to wander into the realm of fantasy.
The solution to this problem is chunking. Files are stripped of all superfluous ballast and broken down into smaller pieces, which are then made available to the language model as independent files. Meaningful chunking is a complex task and a well-kept secret of specialized AI service providers.
The results are much more reliable with chunking, but the method reaches its limits not only with large amounts of data. It is not practical for dynamic data.
RAG
This is where Retrieval Augmented Generation (RAG) comes in. RAG combines internal company data with a language model in such a way that the language model always favors the internal data. The model always looks for an answer in the company's own data before resorting to general knowledge. This significantly increases the accuracy of responses.
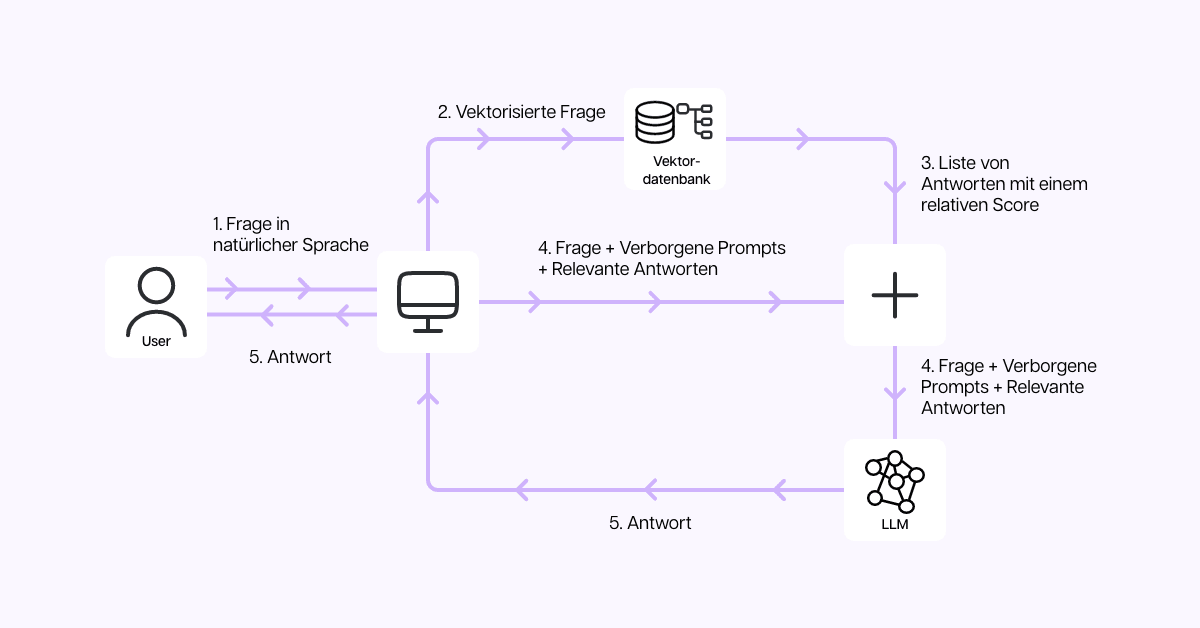
RAG has quickly gained acceptance because it is cheaper than fine-tuning and largely solves the problem of hallucinations. In addition, the data sources are clearly traceable, which creates trust.
Moreover, a RAG project is the prototype of an AI project. It can start small, for example with just a few data sources, and be expanded iteratively. Even a small database can improve the efficiency and quality of a department. As its size and the information stored in it grows, so does the quality and efficiency.
But as nice as it sounds, the reality is often not. The success of RAG depends on data quality and other factors we know from digital projects. More on that in the next episode.